模型
GPT4All 经过优化,可在消费级硬件上运行参数范围为 30 亿至 130 亿的大型语言模型(LLMs)。
LLMs 会被下载到您的设备上,因此您可以在本地私密地运行它们。借助我们的后端,任何人都可以在自己的硬件上高效安全地与 LLMs 进行交互。
下载模型
下载模型
| 1. | 点击左侧菜单中的 Models(位于 Chats 下方、LocalDocs 上方) |
|
| 2. | 点击 + Add Model 导航到 Explore Models 页面 |
 |
| 3. | 搜索在线可用模型 |  |
| 4. | 点击 Download 将模型保存到您的设备 |
 |
| 5. | 模型下载完成后,您会在 Models 中看到它。 |
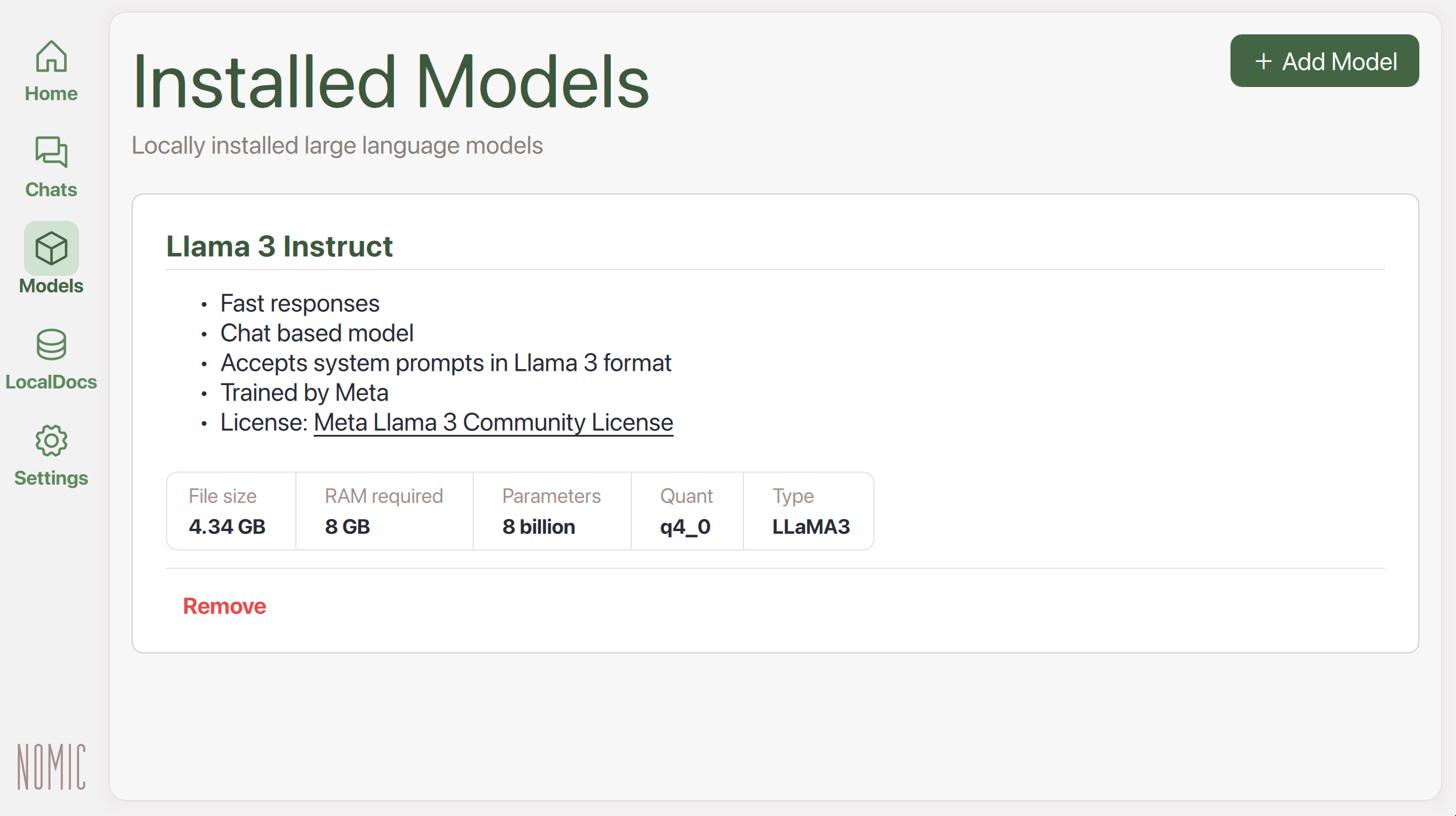 |
探索模型
GPT4All 通过 llama.cpp 后端连接 HuggingFace 上的 LLMs,以便它们可以在您的硬件上高效运行。许多这些模型可以通过文件类型 .gguf 来识别。
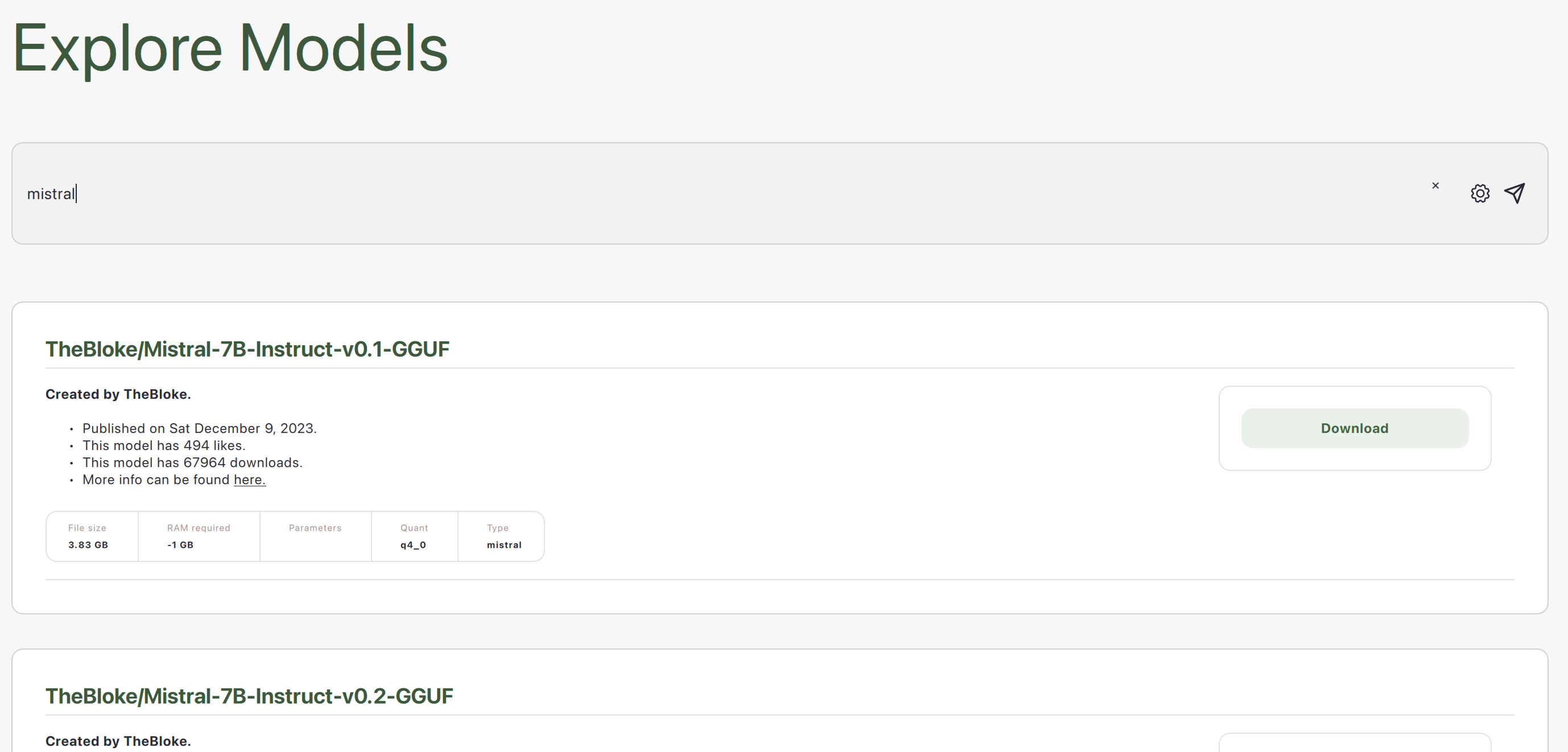
示例模型
许多 LLMs 以不同的尺寸、量化方式和许可证提供。
-
参数更多的 LLMs 在连贯地响应指令方面往往表现更好
-
量化更小的 LLMs(例如 4bit 而不是 16bit)速度更快,内存占用更少,而且性能往往略有下降
-
许可证在个人使用和商业使用条款上有所不同
以下是一些示例
| 模型 | 文件大小 | 所需内存 | 参数 | 量化 | 开发者 | 许可证 | MD5 校验和 (唯一哈希) |
|---|---|---|---|---|---|---|---|
| Llama 3 Instruct | 4.66 GB | 8 GB | 80 亿 | q4_0 | Meta | Llama 3 许可证 | c87ad09e1e4c8f9c35a5fcef52b6f1c9 |
| Nous Hermes 2 Mistral DPO | 4.11 GB | 8 GB | 70 亿 | q4_0 | Mistral 和 Nous Research | Apache 2.0 | Coa5f6b4eabd3992da4d7fb7f020f921eb |
| Phi-3 Mini Instruct | 2.18 GB | 4 GB | 40 亿 | q4_0 | Microsoft | MIT | f8347badde9bfc2efbe89124d78ddaf5 |
| Mini Orca (小型) | 1.98 GB | 4 GB | 30 亿 | q4_0 | Microsoft | CC-BY-NC-SA-4.0 | 0e769317b90ac30d6e09486d61fefa26 |
| GPT4All Snoozy | 7.37 GB | 16 GB | 130 亿 | q4_0 | Nomic AI | GPL | 40388eb2f8d16bb5d08c96fdfaac6b2c |
搜索结果
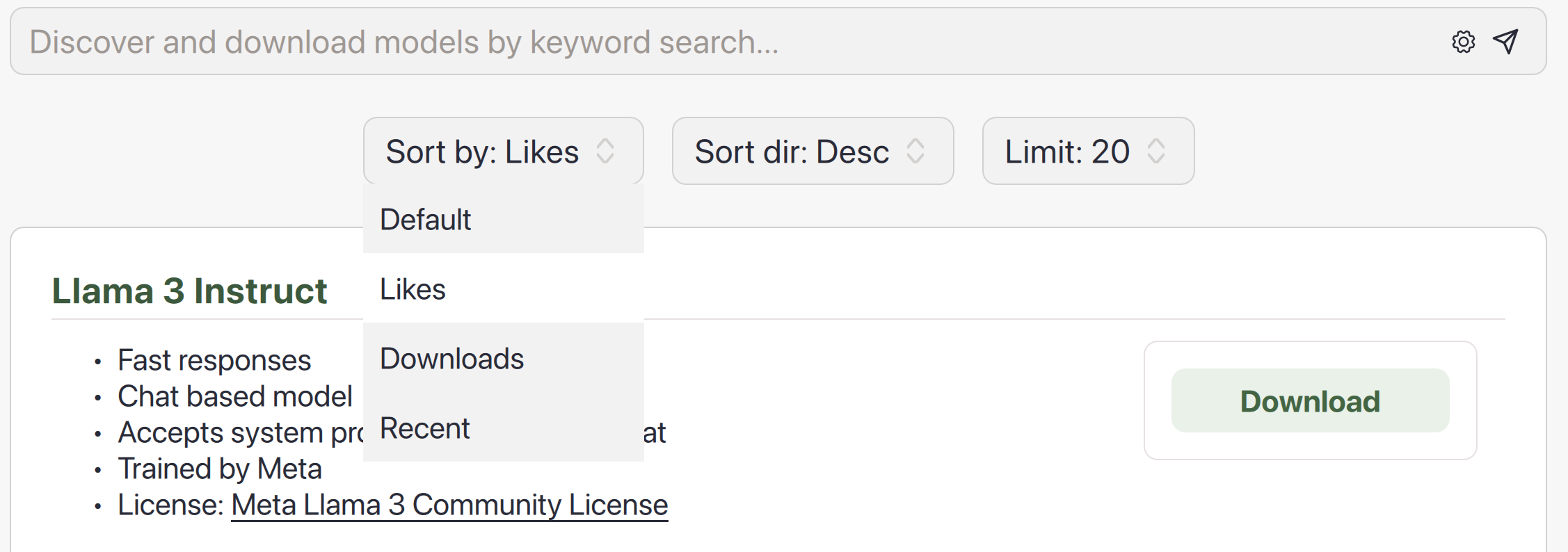
您可以点击搜索栏中的齿轮图标,根据模型的点赞数、下载次数或上传日期(全部来自 HuggingFace)对搜索结果进行排序。
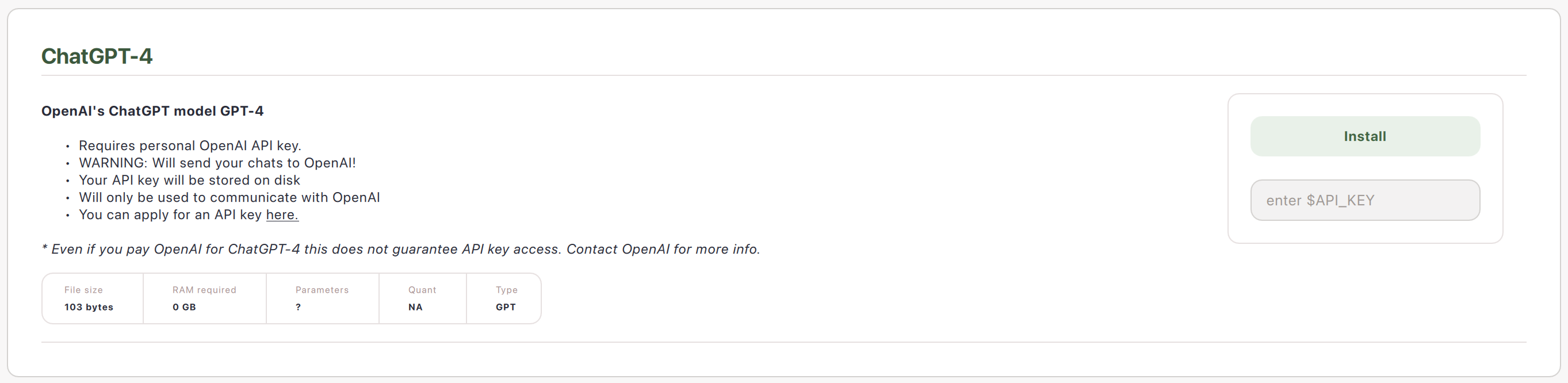
连接模型 API
您可以添加远程模型提供商的 API 密钥。
注意:这不会将模型文件下载到您的计算机上以供安全使用。相反,这种与模型交互的方式会将您的提示从计算机发送到 API 提供商,然后将响应返回到您的计算机。