GPT4All Python SDK
安装
要开始使用,请在你的 python 环境中通过 pip 安装 gpt4all 包。
我们建议使用 venv 或 conda 将 gpt4all 安装到其自己的虚拟环境中。
加载 LLM
模型通过 GPT4All 类按名称加载。如果这是你第一次加载模型,它将被下载到你的设备并保存,以便下次创建同名 GPT4All 模型时可以快速重新加载。
加载 LLM
GPT4All 模型名称 |
文件大小 | 所需内存 | 参数 | 量化 | 开发者 | 许可证 | MD5 和 (唯一哈希) |
|---|---|---|---|---|---|---|---|
Meta-Llama-3-8B-Instruct.Q4_0.gguf |
4.66 GB | 8 GB | 80 亿 | q4_0 | Meta | Llama 3 许可证 | c87ad09e1e4c8f9c35a5fcef52b6f1c9 |
Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf |
4.11 GB | 8 GB | 70 亿 | q4_0 | Mistral & Nous Research | Apache 2.0 | Coa5f6b4eabd3992da4d7fb7f020f921eb |
Phi-3-mini-4k-instruct.Q4_0.gguf |
2.18 GB | 4 GB | 38 亿 | q4_0 | Microsoft | MIT | f8347badde9bfc2efbe89124d78ddaf5 |
orca-mini-3b-gguf2-q4_0.gguf |
1.98 GB | 4 GB | 30 亿 | q4_0 | Microsoft | CC-BY-NC-SA-4.0 | 0e769317b90ac30d6e09486d61fefa26 |
gpt4all-13b-snoozy-q4_0.gguf |
7.37 GB | 16 GB | 130 亿 | q4_0 | Nomic AI | GPL | 40388eb2f8d16bb5d08c96fdfaac6b2c |
聊天会话生成
你可以从 HuggingFace 访问的大多数语言模型都已作为助手进行训练。这引导语言模型不仅回答相关的文本,而且回答有用的文本。
如果你希望你的 LLM 的响应在典型意义上是“有用”的,我们建议你应用模型经过微调时使用的聊天模板。关于特定提示模板的信息通常可以在模型的官方 HuggingFace 页面上找到。
LLM 聊天会话生成示例
加载 Llama 3 并在聊天会话中输入以下提示:
使用默认的采样设置,你应该会看到类似以下内容:
The quadratic formula!
The quadratic formula is a mathematical formula that provides the solutions to a quadratic equation of the form:
ax^2 + bx + c = 0
where a, b, and c are constants. The formula is:
x = (-b ± √(b^2 - 4ac)) / 2a
Let's break it down:
* x is the variable we're trying to solve for.
* a, b, and c are the coefficients of the quadratic equation.
* ± means "plus or minus".
* √ denotes the square root.
To use the formula, simply plug in the values of a, b, and c into the expression above. The resulting value(s) will be the solutions to the original quadratic equation!
For example, let's say we have the quadratic equation:
x^2 + 5x + 6 = 0
We can plug these values into the formula as follows:
a = 1
b = 5
直接生成
直接调用 model.generate() 会提示模型,但不应用任何模板。
注意:这可能导致响应不像有用的回答,而更像是模仿你提示的语气。一般来说,聊天会话之外的语言模型更像是一个反映模型训练数据分布的透镜,而不是一个有用的助手。
作为一个例子,看看当我们给出与上面相同的提示但不应用聊天会话时,模型的响应如何变化:
LLM 直接生成示例
加载 Llama 3 并输入以下提示:
使用默认的采样设置,你应该会看到类似以下内容:
. The equation is in the form of a + bx = c, where a and b are constants.
The solution to this problem involves using the quadratic formula which states that for any quadratic equation ax^2+bx+c=0, its solutions can be found by:
x = (-b ± √(b^2-4ac)) / 2a
In your case, since you have a + bx = c, we need to rewrite it in the form of ax^2+bx+c=0. To do this, subtract both sides from c, so that:
c - (a + bx) = 0
Now, combine like terms on the left side and simplify:
ax^2 + (-b)x + (c-a) = 0\n\nSo now we have a quadratic equation in standard form: ax^2+bx+c=0. We can use this to find its solutions using the quadratic formula:
x = ((-b ± √((-b)^2
为什么它的响应不同?因为语言模型在被微调成助手之前,被训练得更像是一个数据模仿者而不是有用的助手。因此,我们的响应最终更像数学风格文本的典型延续,而不是对话中有用的答案。
嵌入
Nomic 训练并开源免费的嵌入模型,这些模型将在你的硬件上快速运行。
在本地运行文本嵌入模型最简单的方法是使用 nomic python 库来与我们快速的 C/C++ 实现进行交互。
嵌入生成示例
从 nomic 库导入 embed 后,你可以调用 embed.text() 并设置 inference_mode="local"。这将下载一个嵌入模型并保存以备后用。
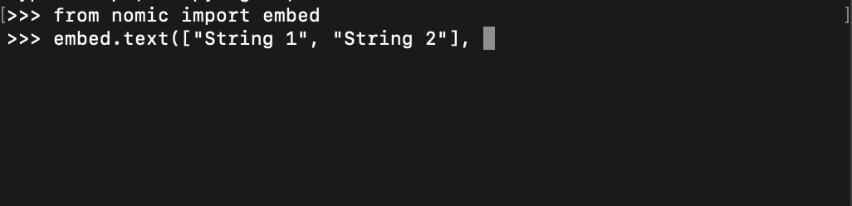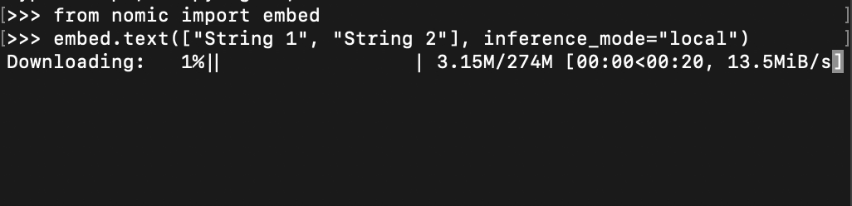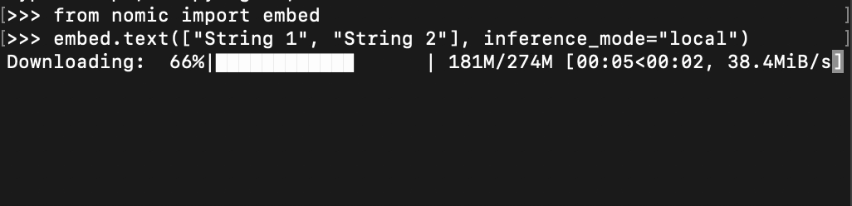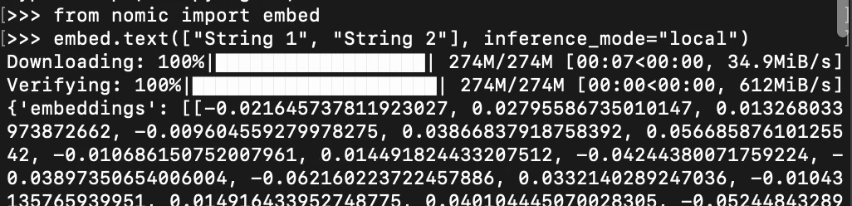
要了解更多关于使用 nomic 进行本地嵌入生成的信息,请访问我们的嵌入指南。
以下嵌入模型可在应用程序中使用,并可通过 gpt4all Python 库中的 Embed4All 类使用。作为 GGUF 文件,默认上下文长度为 2048,但可以扩展。
| 名称 | 与 nomic 一起使用 |
Embed4All 模型名称 |
上下文长度 | # 嵌入维度 | 文件大小 |
|---|---|---|---|---|---|
| Nomic Embed v1 | embed.text(strings, model="nomic-embed-text-v1", inference_mode="local") |
Embed4All("nomic-embed-text-v1.f16.gguf") |
2048 | 768 | 262 MiB |
| Nomic Embed v1.5 | embed.text(strings, model="nomic-embed-text-v1.5", inference_mode="local") |
Embed4All("nomic-embed-text-v1.5.f16.gguf") |
2048 | 64-768 | 262 MiB |
| SBert | 不适用 | Embed4All("all-MiniLM-L6-v2.gguf2.f16.gguf") |
512 | 384 | 44 MiB |